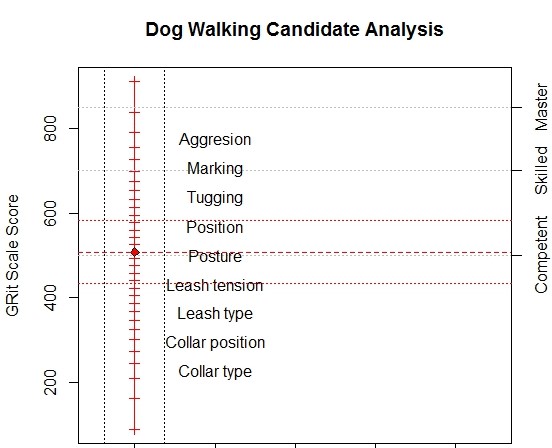
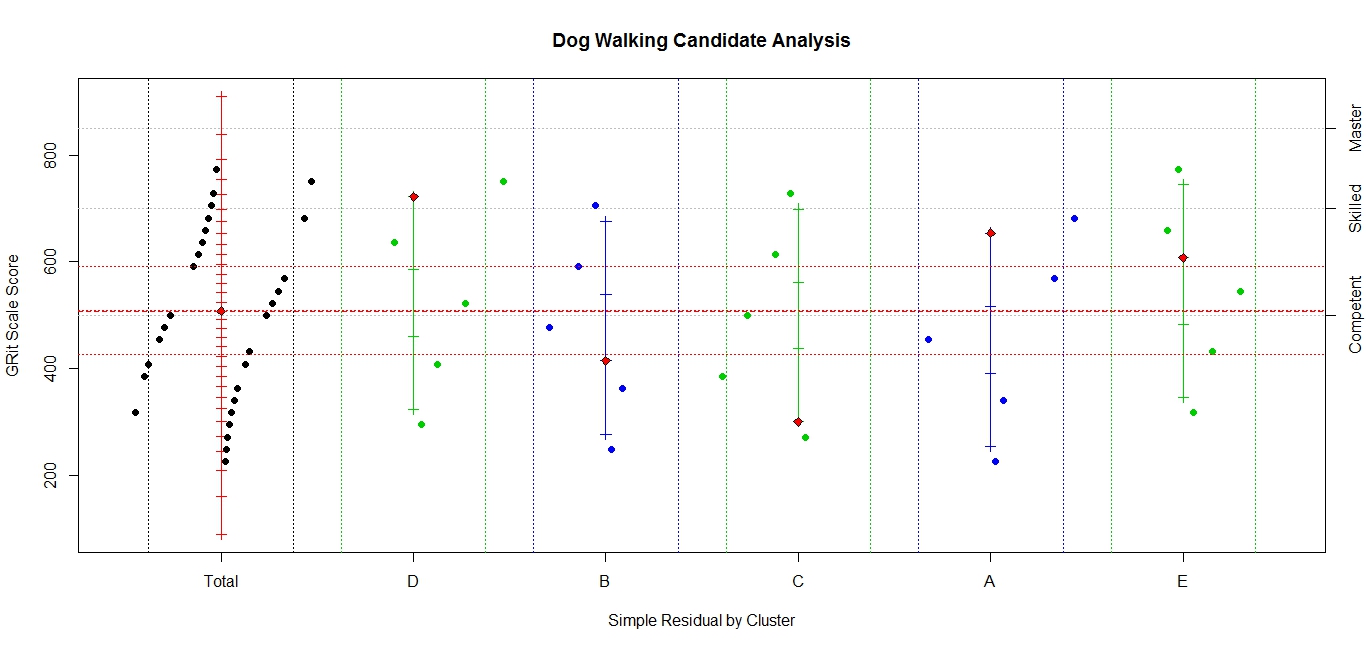
The mathematical, statistical, and philosophical faces of Rasch measurement are separability, sufficiency, and specific objectivity. ‘Separable’ because the person parameter and the item parameter interact in a simple way; Β/Δ in the exponential metric or β-δ in the log metric. ‘Sufficient’ because ‘nuisance’ parameters can be conditioned out so that, in most cases, the number of correct responses is the sufficient statistic for the person’s ability or the item’s difficulty. Specific Objectivity is Rasch’s term for ‘fundamental measurement’; what Wright called ‘sample-free item calibration’. It is objective because it does not depend on the specific sample of items or people; it is specific because it may not apply universally and the validity in any new application must be established.
I add two more ‘S‘s to the trinity: simplicity and symmetry.
Simplicity
We have talked ad nauseum about simplicity. It in fact is one of my favorite themes. The chances that the person will answer the item correctly is Β / (Β + Δ), which is about as simple as life gets.1 Or in less-than-elegant prose:
The likelihood that the person wins is the odds of the person winning
divided by sum of the odds for person winning and the odds for the item winning.
With such a simple model, the sufficient statistics are simple counts, and the estimators can be as simple as row averages. Rasch (1960) did many of his analyses graphically; Wright and Stone (1979) give algorithms for doing the arithmetic, somewhat laboriously, without the benefit of a computer. The first Rasch software at the University of Chicago (CALFIT and BICAL) ran on a ‘mini-computer’ that wouldn’t fit in your kitchen and had one millionth the capacity of your phone.
Symmetry
The first level of symmetry with Rasch models is that person ability and item difficulty have identical status. We can flip the roles of ability and difficulty in everything I have said in this post and every preceding one, or in everything Rasch or Gerhardt Fischer has ever written, and nothing changes. It makes just as much sense to say Δ / (Δ + Β) as Β / (Β + Δ). Granted we could be talking about anti-ability and anti-difficulty, but all the relationships are just the same as before. That’s almost too easy.
Just as trivially, we have noted, or at least implied, that we can flip, as suits our purposes, between the logistic and exponential expressions of the models without changing anything. In the exponential form, we are dealing with the odds that a person passes the standard item; in the logistic form, we have the log odds. If we observe one, we observe the other and the relationships among items and students are unchanged in any fundamental way. We are not limited to those two forms. Using base e is mathematically convenient, but we can choose any other base we like; 10, or 100, or 91 are often used in converting to ‘scale scores’. Any of these transformations preserves all the relationships because they all preserve the underlying interval scale and the relative positions of objects and agents on it.
That’s the trivial part.
Symmetry was a straightforward concept in mathematics: Homo sapiens, all vertebrates, and most other fauna have bilateral symmetry; a snowflake has sixfold; a sphere an infinite number. The more degrees of symmetry, the fewer parameters that are required to describe the object. For a sphere, only one, the radius, is needed and that’s as low as it goes.
Leave it to physicists to take an intuitive idea and made it into a topic for advanced graduate seminars2:
A symmetry of a physical system is a physical or mathematical feature of the system
(observed or intrinsic)
that is preserved or remains unchanged under some transformation.
For every invariant (i.e., symmetry) in the universe, there is a conservation law.
Equally, for every conservation law in physics, there is an invariant.
(Noether’s Theorem, 1918)3.
Right. I don’t understand enough of that to wander any deeper into space, time, or electromagnetism or to even know if this sentence makes any sense.
In Rasch’s world,4 when specific objectivity holds, the ‘difficulty’ of an item is preserved whether we are talking about high ability students or low, fifth graders or sixth, males or females, North America or British Isles, Mexico or Puerto Rico, or any other selection of students that might be thrust upon us.
Rasch is not suggesting that the proportion answering the item correctly (aka, p-value) never varies or that it doesn’t depend on the population tested. In fact, just the opposite, which is what makes p-values and the like ” rather scientifically uninteresting”. Nor do we suggest that the likelihood that a third grader will correctly add two unlike fractions is the same as the likelihood for a nineth grader. What we are saying is that there is an aspect of the item that is preserved across any partitioning of the universe; that the fraction addition problem has its own intrinsic difficulty unrelated to any student.
“Preserved across any partitioning of the universe” is a very strong statement. We’re pretty sure that kindergarten students and graduate students in Astrophysics aren’t equally appropriate for calibrating a set of math items. And frankly, we don’t much care. We start caring if we observe different difficulty estimates from fourth-grade boys or girls, or from Blacks, Whites, Asians, or Hispanics, or from different ability clusters, or in 2021 and 2022. The task is to establish not if it ever fails but when symmetry holds.
I need to distinguish a little more carefully between the “latent trait” and our quantification of locations on the scale. An item has an inherent difficulty that puts it somewhere along the latent trait. That location is a property of the item and does not depend on any group of people that have been given, or that may ever be given the item. Nor does it matter if we choose to label it in yards or meters, Fahrenheit or Celsius, Wits or GRits. This property is what it is whether we use the item for a preschooler, junior high student, astrophysicist, or Supreme Court Justice. This we assume is invariant. Even IRTists understand this.
Although the latent trait may run the gamut, few items are appropriate for use in more than one of the groups I just listed. That would be like suggesting we can use the same thermometer to assess the status of a feverish preschooler that we use for the surface of the sun, although here we are pretty sure we are talking about the same latent ‘trait’. It is equally important to choose an appropriate sample for calibrating the items. A group of preschoolers could tell us very little about the difficulty of items appropriate for assessing math proficiency of astrophysicists.
Symmetry can break in our data for a couple reasons. Perhaps there is no latent trait that extends all the way from recognizing basic shapes to constructing proofs with vector calculus. I am inclined to believe there is in this case, but that is theory and not my call. Or perhaps we did not appropriately match the objects and agents. Our estimates of locations on the trait should be invariant regardless of which objects and agents we are looking at. If there is an issue, we will want to know why: are difficulty and ability poorly matched? Is there a smart way to get the item wrong? Is there a not-smart way to get it right? Is the item defective? Is the person misbehaving? Or did the trait shift? Is there a singularity?
My physics is even weaker that my mathematics.
What most people call ‘Goodness of Fit’ and Rasch called ‘Control of the Model’, we are calling an exploration of the limits of symmetry. For me, I have a new buzz word, but the question remains, “Why do bright people sometimes miss easy items and non-bright people sometimes pass hard items?”5 This isn’t astrophysics.
Here is my “item response theory”:
The Rasch Model is a main effects model; the sufficient statistics for ability and difficulty are the row and column totals of the item response matrix. Before we say anything important about the students or items, we need to verify that there are no interactions. This means no matter how we sort and block the rows, estimates of the column parameters are invariant (enough).
That’s me regressing to my classical statistical training to say that symmetry holds for these data.
[1] It may look more familiar but less simple if we rewrite it as (Β/Δ) / (1 + Β/Δ), even better eβ-δ/(1 + eβ-δ), but it’s all the same for any observer.
[2] Both of the following statements were lifted (plagiarized?) from a Wikipedia discussion of symmetry. I deserve no credit for the phrasing, nor do I seek it.
[3] Emmy Noether was a German mathematician whose contributions, among other things, changed the science of physics by relating symmetry and conservation. The first implication of her theorem was it solved Hilbert and Einstein’s problem that General Relativity appeared to violate the conservation of energy. She was generally unpaid and dismissed, notably and empathically not by Hilbert and Einstein, because she was a woman and a Jew. In that order.
When Göttingen University declined to give her a paid position, Hilbert responded, “Are we running a University or a bathing society?” In 1933, all Jews were forced out of academia in Germany; she spent the remainder of her career teaching young women at Bryn Mawr College and researching at the Institute for Advanced Study in Princeton (See Einstein, A.)
[4] We could flip this entire conversation and talk about the ‘ability’ of a person preserved across shifts of item difficulty, type, content, yada, yada, yada, and it would be equally true. But I repeat myself again.
[5] Except for the ‘boy meets girl, . . . aspect, this question is the basic plot of “Slumdog Millionaire“, undoubtedly the greatest psychometric movie ever made. I wouldn’t however describe the protagonist as “non-bright”, which suggests there is something innate in whatever trait is operating and exposes some of the flaws in my use of the rather pejorative term. I should use something more along the lines of “poorly schooled” or “untrained”, placing effort above talent.